✓
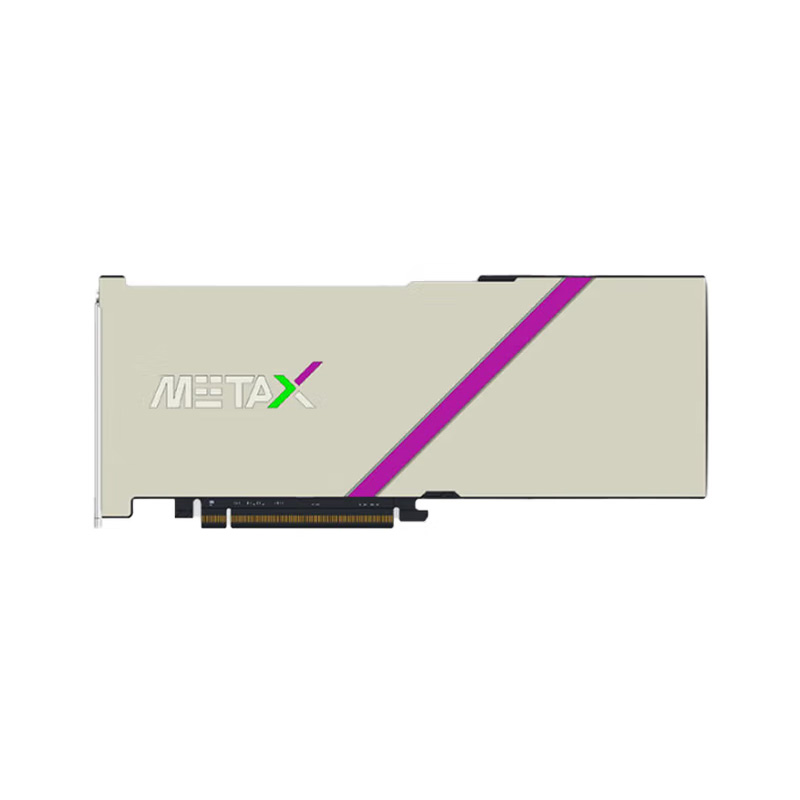
Model: xi Si N260 (MXN260) 64GB domestic high-end training and inference integrated GPU.
✓
Optimized for AI large model training/inference and scientific computing.
✓
Performance Standards: Comparable to L20 series.
✓
FP32 Performance: 15 TFLOPS computing speed.
✓
FP16 Performance: 80 TFLOPS computing speed.
✓
INT8 Precision: 160 TOPS performance throughput.
✓
HBM2E Memory: Features high bandwidth memory, with approximately 30% higher bandwidth compared to HBM2.
✓
Manufacturing Process: TSMC 7nm FinFET process paired with 2.5D CoWoS advanced packaging for heat dissipation.
✓
Dedicated non-graphics rendering positioning (No game/graphics related API adaptation).
✓
Effective Frequency: 9.375Gbps paired with 1.2TB/s memory bandwidth capacity.
✓
Bus Width: 1024bit complying with industry HBM2 specifications.
✓
Memory Latency: ~7ns corresponding to an equivalent frequency of 4000 MHz.
✓
Video Output: Focused data center computing design (no traditional DP/HDMI/VGA ports).
✓
Core Interface: PCIe Gen4.0 x16 (bidirectional bandwidth 64GB/s) supporting x86/ARM hosts.
✓
Form Factor: FHFL dual-slot hardware architecture.
✓
Total Weight: 1064g enterprise build.